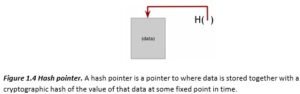
A hash pointer is a data structure that turns out to be useful in many of the systems that we will talk about. A hash pointer is simply a pointer to where some information is stored together with a cryptographic hash of the information. Whereas a regular pointer gives you a way to retrieve the information, a hash pointer also gives you a way to verify that the information hasn’t changed.
We can use hash pointers to build all kinds of data structures. Intuitively, we can take a familiar data structure that uses pointers such as a linked list or a binary search tree and implement it with hash pointers, instead of pointers as we normally would.
Block chain. In Figure 1.5, we built a linked list using hash pointers. We’re going to call this data structure a block chain. Whereas as in a regular linked list where you have a series of blocks, each block has data as well as a pointer to the previous block in the list, in a block chain the previous block pointer will be replaced with a hash pointer. So each block not only tells us where the value of the previous block was, but it also contains a digest of that value that allows us to verify that the value hasn’t changed. We store the head of the list, which is just a regular hash‐pointer that points to the most recent data block.

A use case for a block chain is a tamper‐evident log. That is, we want to build a log data structure that stores a bunch of data, and allows us to append data onto the end of the log. But if somebody alters data that is earlier in the log, we’re going to detect it.
To understand why a block chain achieves this tamper‐evident property, let’s ask what happens if an adversary wants to tamper with data that’s in the middle of the chain. Specifically, the adversary’s goal is to do it in such a way that someone who remembers only the hash pointer at the head of the block chain won’t be able to detect the tampering. To achieve this goal, the adversary changes the data of some block k. Since the data has been changed, the hash in block k + 1, which is a hash of the entire block k, is not going to match up. Remember that we are statistically guaranteed that the new hash will not match the altered content since the hash function is collision resistant. And so we will detect the inconsistency between the new data in block k and the hash pointer in block k + 1. Of course the adversary can continue to try and cover up this change by changing the next block’s hash as well. The adversary can continue doing this, but this strategy will fail when he reaches the head of the list. Specifically, as long as we store the hash pointer at the head of the list in a place where the adversary cannot change it, the adversary will be unable to change any block without being detected.
The upshot of this is that if the adversary wants to tamper with data anywhere in this entire chain, in order to keep the story consistent, he’s going to have to tamper with the hash pointers all the way back to the beginning. And he’s ultimately going to run into a roadblock because he won’t be able to tamper with the head of the list. Thus it emerges, that by just remembering this single hash pointer, we’ve essentially remembered a tamper‐evident hash of the entire list. So we can build a block chain like this containing as many blocks as we want, going back to some special block at the beginning of the list, which we will call the genesis block.
You may have noticed that the block chain construction is similar to the Merkle‐Damgard construction that we saw in the previous section. Indeed, they are quite similar, and the same security argument applies to both of them.

Merkle trees. Another useful data structure that we can build using hash pointers is a binary tree. A binary tree with hash pointers is known as a Merkle tree, after its inventor Ralph Merkle. Suppose we have a number of blocks containing data. These blocks comprise the leaves of our tree. We group these data blocks into pairs of two, and then for each pair, we build a data structure that has two hash pointers, one to each of these blocks. These data structures make the next level up of the tree. We in turn group these into groups of two, and for each pair, create a new data structure that contains the hash of each. We continue doing this until we reach a single block, the root of the tree.
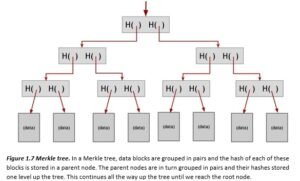
As before, we remember just the hash pointer at the head of the tree. We now have the ability traverse down through the hash pointers to any point in the list. This allows us make sure that the data hasn’t been tampered with because, just like we saw with the block chain, if an adversary tampers with some data block at the bottom of the tree, that will cause the hash pointer that’s one level up to not match, and even if he continues to tamper with this block, the change will eventually propagate to the top of the tree where he won’t be able to tamper with the hash pointer that we’ve stored. So again, any attempt to tamper with any piece of data will be detected by just remembering the hash pointer at the top.
Proof of membership. Another nice feature of Merkle trees is that, unlike the block chain that we built before, it allows a concise proof of membership. Say that someone wants to prove that a certain data block is a member of the Merkle Tree. As usual, we remember just the root. Then they need to show us this data block, and the blocks on the path from the data block to the root. We can ignore the rest of the tree, as the blocks on this path are enough to allow us to verify the hashes all the way up to the root of the tree. See Figure 1.8 for a graphical depiction of how this works.
If there are n nodes in the tree, only about log(n) items need to be shown. And since each step just requires computing the hash of the child block, it takes about log(n) time for us to verify it. And so even if the Merkle tree contains a very large number of blocks, we can still prove membership in a relatively short time. Verification thus runs in time and space that’s logarithmic in the number of nodes in the tree.

A sorted Merkle tree is just a Merkle tree where we take the blocks at the bottom, and we sort them using some ordering function. This can be alphabetical, lexicographical order, numerical order, or some other agreed upon ordering.
Proof of non‐membership. With a sorted Merkle tree, it becomes possible to verify non‐membership in a logarithmic time and space. That is, we can prove that a particular block is not in the Merkle tree. And the way we do that is simply by showing a path to the item that’s just before where the item in question would be and showing the path to the item that is just after where it would be. If these two items are consecutive in the tree, then this serves as a proof that the item in question is not included. For if it was included, it would need to be between the two items shown, but there is no space between them as they are consecutive.
We’ve discussed using hash pointers in linked lists and binary trees, but more generally, it turns out that we can use hash pointers in any pointer‐based data structure as long as the data structure doesn’t have cycles. If there are cycles in the data structure, then we won’t be able to make all the hashes match up. If you think about it, in an acyclic data structure, we can start near the leaves, or near the things that don’t have any pointers coming out of them, compute the hashes of those, and then work our way back toward the beginning. But in a structure with cycles, there’s no end we can start with and compute back from.
So, to consider another example, we can build a directed acyclic graph out of hash pointers. And we’ll be able to verify membership in that graph very efficiently. And it will be easy to compute. Using hash pointers in this manner is a general trick that you’ll see time and again in the context of the distributed data structures and throughout the algorithms.














































